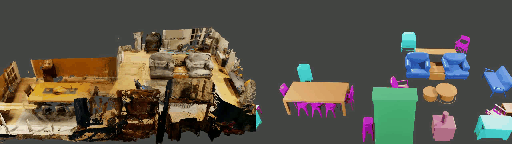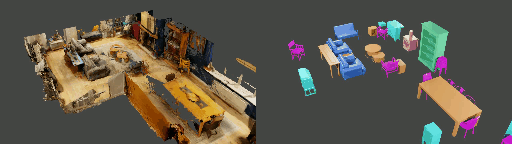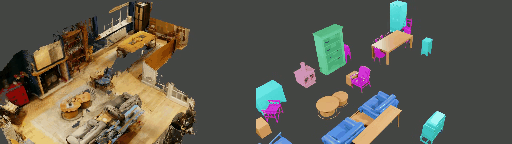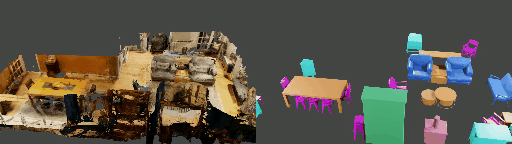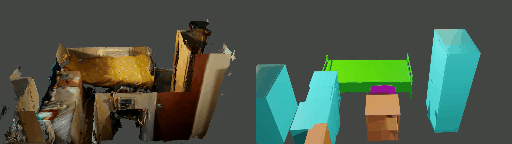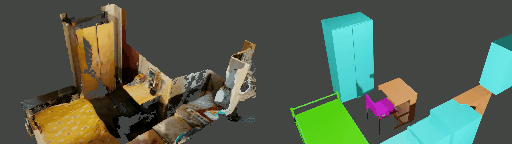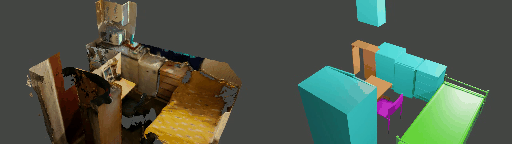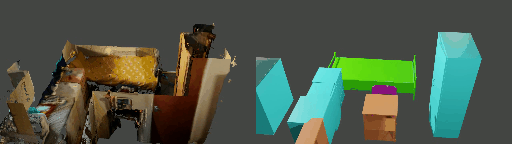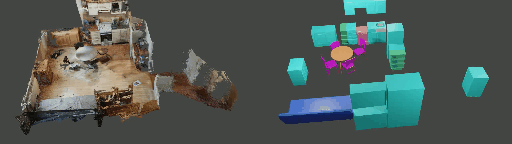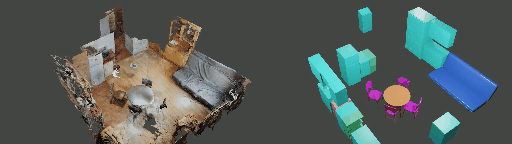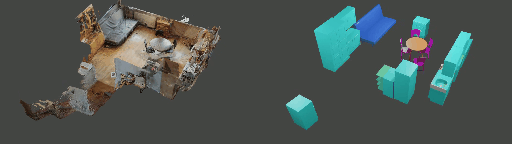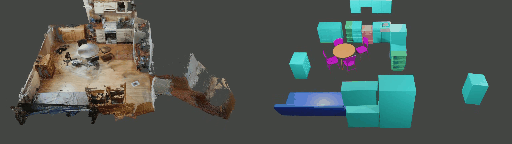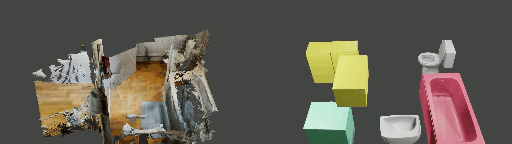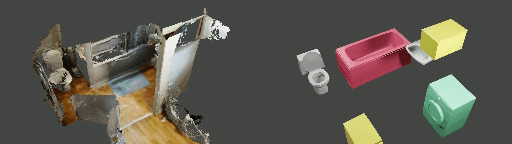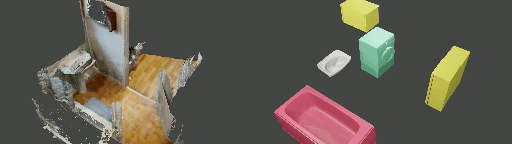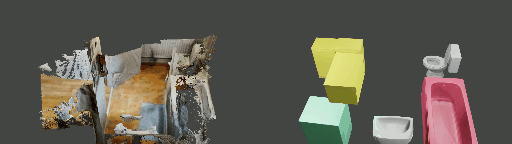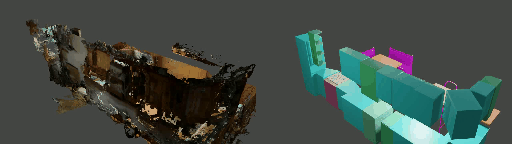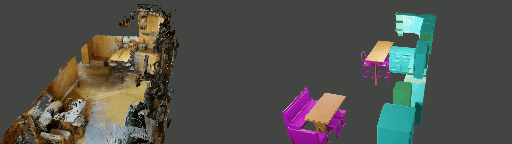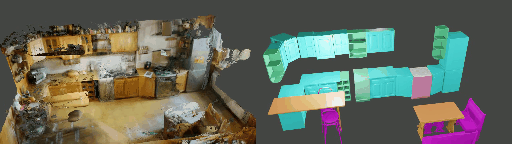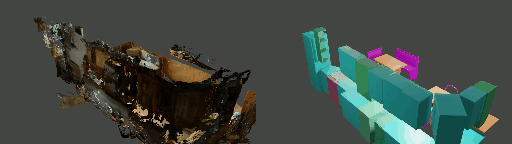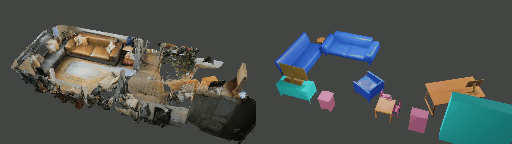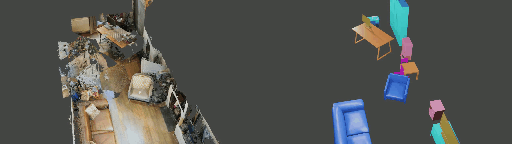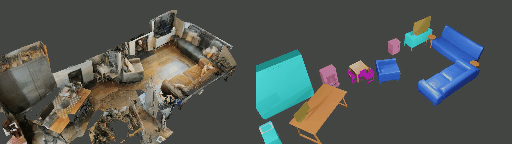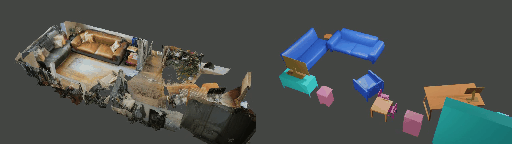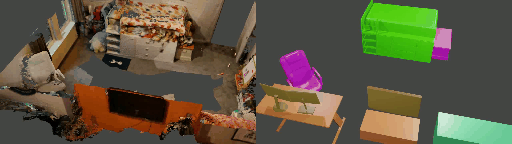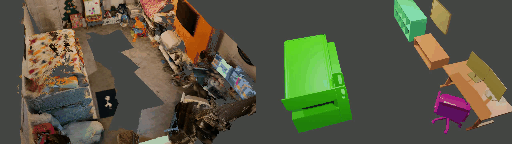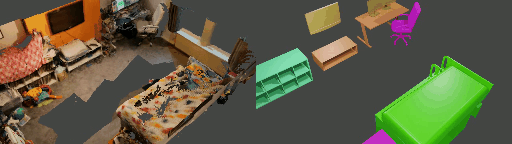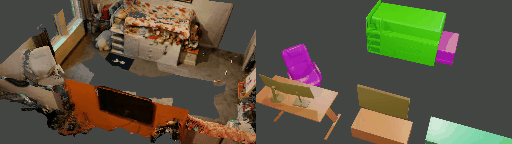Abstract
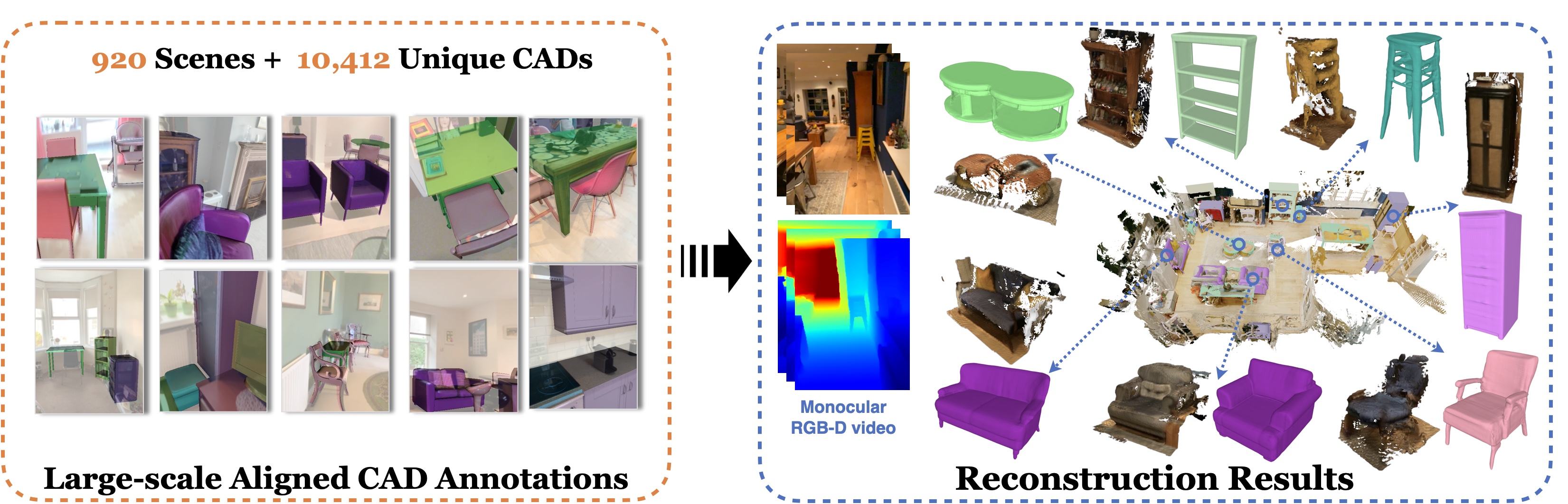
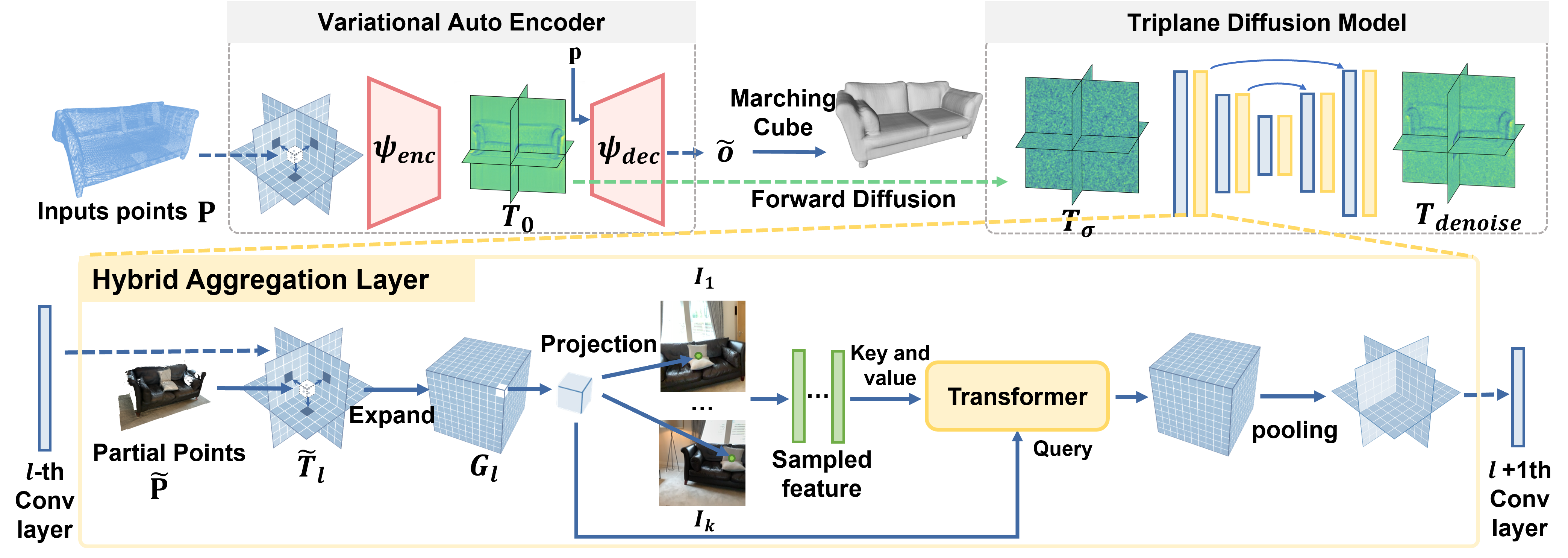
Instance shape reconstruction from a 3D scene involves recovering the full geometries of multiple objects at the semantic instance level. Many methods leverage data-driven learning due to the intricacies of scene complexity and significant indoor occlusions. Training these methods often requires a large-scale, high-quality dataset with aligned and paired shape annotations with real-world scans. Existing datasets are either synthetic or misaligned, restricting the performance of data-driven methods on real data. To this end, we introduce LASA, a Large-scale Aligned Shape Annotation Dataset comprising 10,412 high-quality CAD annotations aligned with 920 real-world scene scans from ArkitScenes, created manually by professional artists. On this top, we propose a novel Diffusion-based Cross-Modal Shape Reconstruction (DisCo) method. It is empowered by a hybrid feature aggregation design to fuse multi-modal inputs and recover high-fidelity object geometries. Besides, we present an Occupancy-Guided 3D Object Detection (OccGOD) method and demonstrate that our shape annotations provide scene occupancy clues that can further improve 3D object detection. Supported by LASA, extensive experiments show that our methods achieve state-of-the-art performance in both instance-level scene reconstruction and 3D object detection tasks.